本项目旨在完成P2P互联网金融行业的风险分析,建立标准化的风险测评维度和风险测评模型,识别高风险P2P互联网金融企业,最终生成自动化P2P互联网金融企业风险分析报告。
本项目选取了P2P互联网金融行业中八百余家代表性企业,基于这些企业多方面、多维度的海量历史数据,选取了恰当的风险测评维度,建立风险测评模型,分析这些P2P互联网金融企业目前所面临的风险,并对各个企业的整体风险状况及其不同领域的风险状况进行评估,生成P2P互联网金融企业风险报告,直观、准确地展示了企业各方面的风险数据、风险指标和风险等级,满足互联网金融监管需求,方便对于互联网金融企业进行风险监控。
技术路线
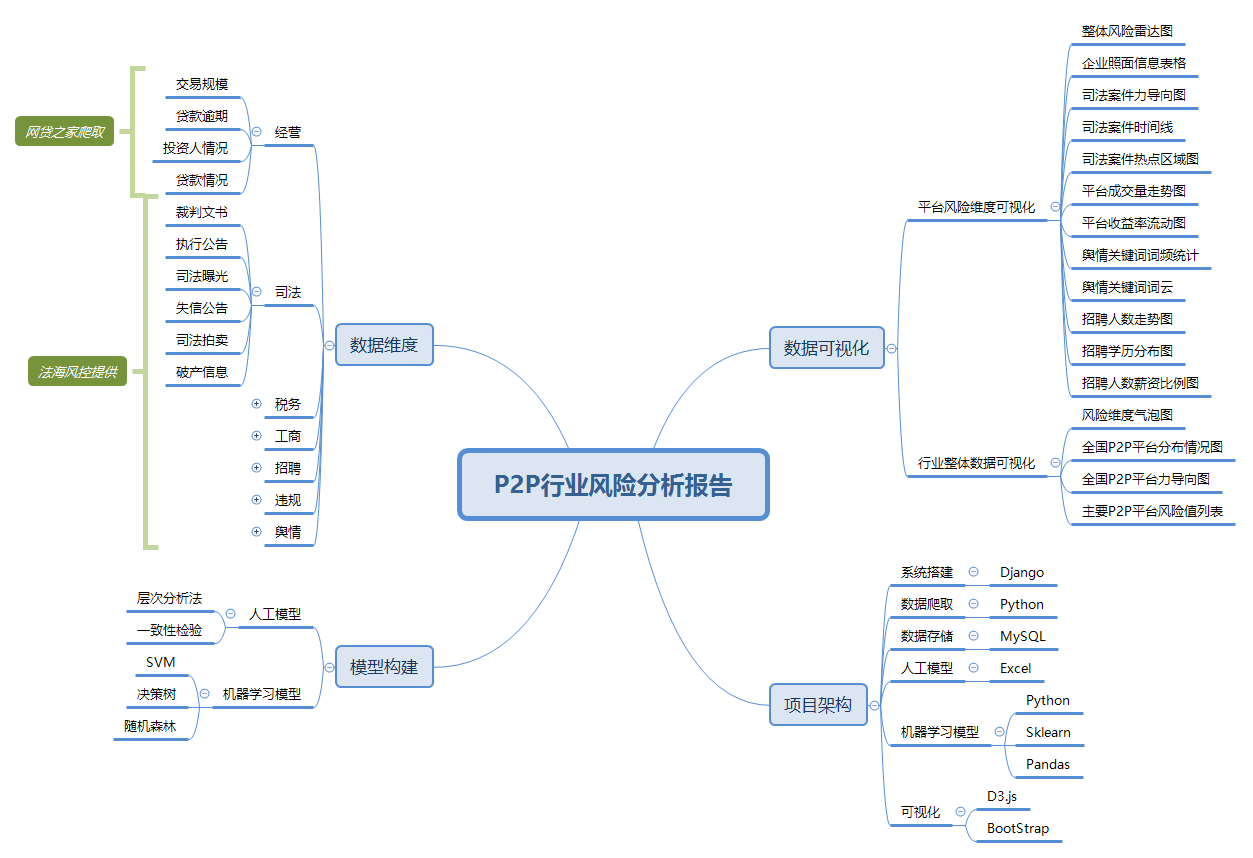
数据维度
选取了司法维度信息(包括裁判文书,执行公告,司法曝光,失信公告,司法拍卖,破产信息),税务维度信息,工商维度信息,招聘维度信息,违规维度信息,舆情维度信息和通过网贷之家爬取的经营维度信息(包括交易规模,贷款逾期,投资人情况,贷款情况等)。获取这些信息后,经过数据清洗,转换(转为统一的CSV格式)和集成,将非格式化的数据存储到结构化的MySQL数据库。
模型构建
对于记录数据较为完整的经营方面的数据,进行机器学习模型的构建。为了使得预测结果更加准确,分别选取了SVM模型,决策树模型,随机森林模型和LightGBM模型对这些数据进行模型的训练和测试,从中选取预测效果最好的模型进行使用。而对于领域知识比较强,数据记录比较少,离散化数据较多的非经营维度指标,采取了层次分析法和一致性检验的方式进行了人工模型的构建。最后将两种模型(人工模型和机器学习模型)进行了交叉验证,保证了模型的正确性。
项目架构
整体项目架构包括最初的数据爬取,数据清洗,数据存储等数据相关的处理流程,以及后续得到人工模型,机器学习模型等模型层面的构建,最后以一个可视化网站的形式进行结果的展示
数据可视化
数据可视化采用D3.js技术,通过后台Django传来的数据,进行可视化效果展示。展示主要包括两个方面:
首先是p2p行业整体数据的可视化,其中包括风险维度气泡图,全国p2p平台分布情况图,全国p2p平台力向导图以及主要p2p平台风险值列表。
其次是具体某个平台风险维度的可视化,其中包括整体风险雷达图,企业照面信息表格,司法案件力导向图,司法案件时间线,司法案件热点区域图,平台成交量走势图,平台收益率流动图,舆情关键词词频统计,舆情关键词词云,招聘人数走势图,招聘学历分布图以及招聘人数薪资比例图等。
风险点甄别
风险维度及说明
| 维度 | 子维度 | 说明 |
|---|---|---|
| 涉诉信息 | 破产信息、司法拍卖、失信公告、司法曝光台、执行公告、裁判文书 | 涉诉信息,即司法信息,描述了企业涉及法律诉讼案件的信息,企业的违法信息,企业被告信息,以及企业涉及司法拍卖和破产的信息。一个企业是否依法经营、是否有违法行为在很大程度上可以反映出一个企业的风险情况,企业行为合法合规是一个企业稳定发展的必要条件,而企业涉诉过多、企业违法行为严重则说明企业存在问题过多,说明企业风险过大。 |
| 工商信息 | 严重违法、工商行政处罚信息、经营异常、关联信息、变更信息、工商公示信息、企业公示信息 | (1)工商信息描述了企业的资本、法人、经营范围等工商基本信息,作为描述企业的重要信息,当工商信息发生异常变动和重要变更时,则说明企业存在异常,可能会出现较高风险。(2)此外项目注重关联方的风险信息。关联信息描述了和该企业相关的其他企业,包括企业和法人的对外投资、子公司等。变更信息描述了工商信息的变更情况,当出现异常变更或较大变更时,意味着其在风险的出现。 |
| 税务信息 | 非正常户、行政处罚、欠税公告、纳税信用等级(ABCD) | 税务信息描述了企业是否按时报税、缴税,曝光了企业欠税漏税的行为,在一定程度上反映出企业信用出现问题。企业出现长期欠税,或被税务部门列为纳税非正常户,说明企业已违反法律犯规,其经营出现异常,可能已经出现财务或资金问题,说明企业存在较大风险。 |
| 经营信息 | 贷款逾期情况、交易规模 | 经营信息数据提取自网贷之家、网贷天眼和和互联网金融等级披露服务平台,通过定量指标评估网贷平台的交易规模和贷款逾期情况。 |
| 舆情信息 | 新闻媒体 | 通过抓取微信、微博和新闻客户端中关于P2P网贷平台的相关信息,分析新闻中是否包含关键词“诈骗、提现困难、逾期、无法访问、收益、利率、红包、加息、监管、存管、坑爹、无语、不透明、造假、自融、曝光、打不通、打不开、频繁变更”等字段,判读新闻事件的严重程度。 |
| 违规信息 | ICP认证、银行存管、央行处罚、银监会处罚 | (1)ICP认证是所有互联网经营必备许可证,若P2P平台无ICP认证记录,则可判定为非法经营。(2)2016年8月出台的《网络贷款资金存款业务指引》要求所有P2P平台完成银行存管。银行存管使得P2P企业自身资金账户与用户资金相隔离,做到资金与交易的分离,避免用户资金被直接挪用。若平台无银行存管记录,则可能出现较高风险。 |
| 招聘信息 | 管理层学历、招聘学历分布、岗位数量与招聘人数 | 项目通过分析平台发布的招聘信息分析平台团队的学历分布,尤其是管理层学历分布。若出现短时间大量无门槛招聘,管理人员岗位严重空缺等情况,则说明平台可能出现风险。 |
项目信用风险评级指标体系
层次分析法,具体指标略。
系统搭建
- D3.js(前端可视化)
- Python+Django(后端请求处理)
- Mysql(后台数据库)
- 访问端口:8000
数据提取及处理
本项目的数据来源主要有2个,一是通过网页爬取的p2p平台的经营信息,二是由企业方提供的工商信息等数据。本节将描述如何通过爬虫提取数据,以及如何处理企业提供的数据,并将其经过数据清洗过程后形成结构化的数据存储在MySQL数据库中。
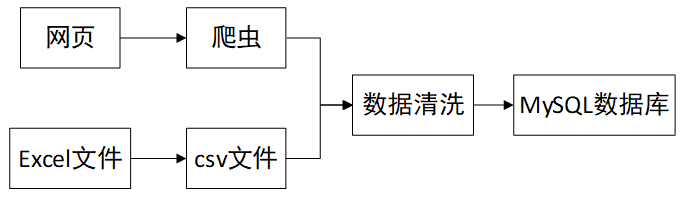
爬虫提取数据
Scrapy框架
Scrapy是基于Python语言开发的一个快速,高层次的web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
数据主要来源
来自各大p2p平台网站,以经营数据为例,选取了网贷之家的平台成交数据和中国互联网金融协会的互联网金融登记披露服务平台的运营信息作为经营数据的来源。在这些网站上可以获取到p2p平台的交易总额、交易总笔数、融资人总数、投资人总数、项目逾期率和金额逾期率等信息,作为数据爬取的对象。
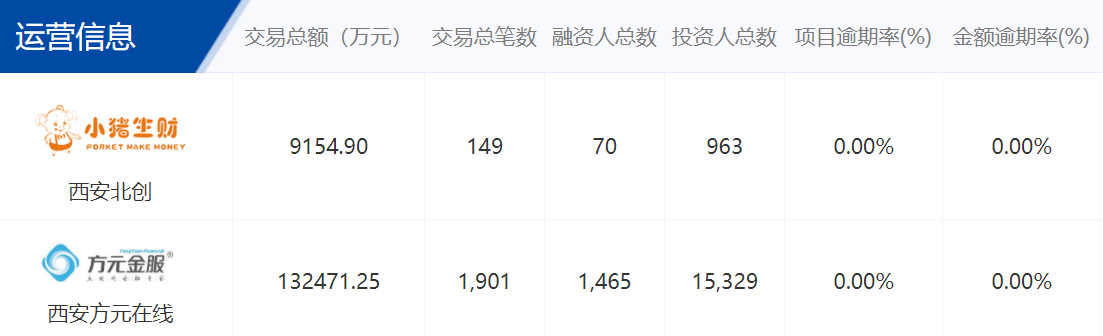

数据获取
由于中国互联网金融协会的互联网金融登记披露服务平台的运营信息在网页上是动态加载的,从网页源代码中对应标签内的数字可以获取到对应的数据,例如下图展示了从网页展示平台成交量到获取成交量的具体数值的过程:

在提取数字过程中还是使用了一些正则表达式用于抽取表格标签中的数据,例如下图展示了正则表达式匹配数字的过程:

而对于网贷之家的平台成交数据,通过查看网页的Javascript代码,找到了网页的json请求接口,然后使用Python和Scrapy框架模拟了data表单的post请求获得了不同时间段的p2p平台经营信息:

爬虫数据的数据库存储
项目使用MySQL数据库存储数据,由于2个信息披露平台的数据格式不同,所以需要建立对应的表结构分别存储网贷之家的平台成交数据和中国互联网金融协会的互联网金融登记披露服务平台的运营信息,所建立的数据表如下:
| 列名 | 含义 |
|---|---|
| bussinessInfo | 互联网金融协会披露经营数据 |
| platform_name | 平台名称 |
| end_time | 信息截止日期 |
| trade_amount | 交易总额(万元) |
| trade_total_number | 交易总笔数(笔) |
| invest_total_number | 投资总笔数(笔) |
| financiers_number | 融资人总数(人) |
| invester_number | 投资人总数(人) |
| repaid_amount | 待偿金额(万元) |
| past_amount | 逾期金额(万元) |
| project_past_rate | 项目逾期率(%) |
| amount_past_rate | 金额逾期率(%) |
| project_past_number | 逾期项目数 |
| average_financialer_amount | 人均累计融资金额(万元) |
| average_invest_amount | 人均累计投资金额(万元) |
| average_finacing_amount | 笔均融资金额(万元) |
| top1_finacing_rate | 最大单户融资余额占比(%) |
| top10_finacing_rate | 最大10户融资余额占比(%) |
| top1_invest_rate | 最大单户投资余额占比(%) |
| top10_invest_rate | 最大10户投资余额占比(%) |
| project_past90_rate | 项目分级逾期率(90天)(%) |
| project_past180_rate | 项目分级逾期率(91-180天)(%) |
| project_past181_rate | 项目分级逾期率(181天以上)(%) |
| amount_past90_rate | 金额分级逾期率(90天)(%) |
| amount_past180_rate | 金额分级逾期率(91-180天)(%) |
| amount_past181_rate | 金额分级逾期率(181天以上)(%) |
| history_project_past_amount | 历史项目逾期金额(万元) |
| history_project_past_rate | 历史项目逾期率(%) |
| total_past_amount | 累计逾期代偿金额(万元) |
| total_past_number | 累计逾期代偿笔数(笔) |
| bussinessInfoId | 交易信息唯一标识符ID |
| 列名 | 含义 |
|---|---|
| wdzjInfo | 网贷之家公布经营数据 |
| wdzjInfoId | 交易信息唯一表示ID |
| platform_name | 平台名称 |
| amount | 成交量(万元) |
| incomeRate | 平均参考收益率(%) |
| loanPeriod | 平均借款期限(月) |
| regCapital | 注册资本 |
| fullloanTime | 满标用时(分) |
| stayStillOfTotal | 待还余额(万元) |
| netInflowOfThirty | 资金净流入(万元) |
| timeOperation | 运营时间 |
| bidderNum | 投资人数 |
| borrowerNum | 借款人数 |
| totalLoanNum | 借款标数 |
| top10DueInProportion | 前十大土豪待收金额占比 |
| avgBidMoney | 人均投资金额 |
| top10StayStillProportion | 前十大借款人待还金额占比 |
| avgBorrowMoney | 人均借款金额 |
| developZhishu | 发展指数排名 |
| currentLeverageAmount | 杠杆金额 |
| startDate | 开始日期 |
| endDate | 截止日期 |
| weightedAmount | 权重金额 |
| background | 背景 |
| newbackground | 新背景 |
企业提供的数据处理
合作企业从司法、税务、工商、舆情、违规和招聘共6个维度提供了相关数据,具体的数据提供形式是excel表格的文件形式,所以需要将其转化为csv文件格式便于后续的处理。csv文件是以逗号的分隔的文本,这里使用python读取csv文件,将每一行文本按照逗号分割后导入MySQL数据库中。
数据库表结构
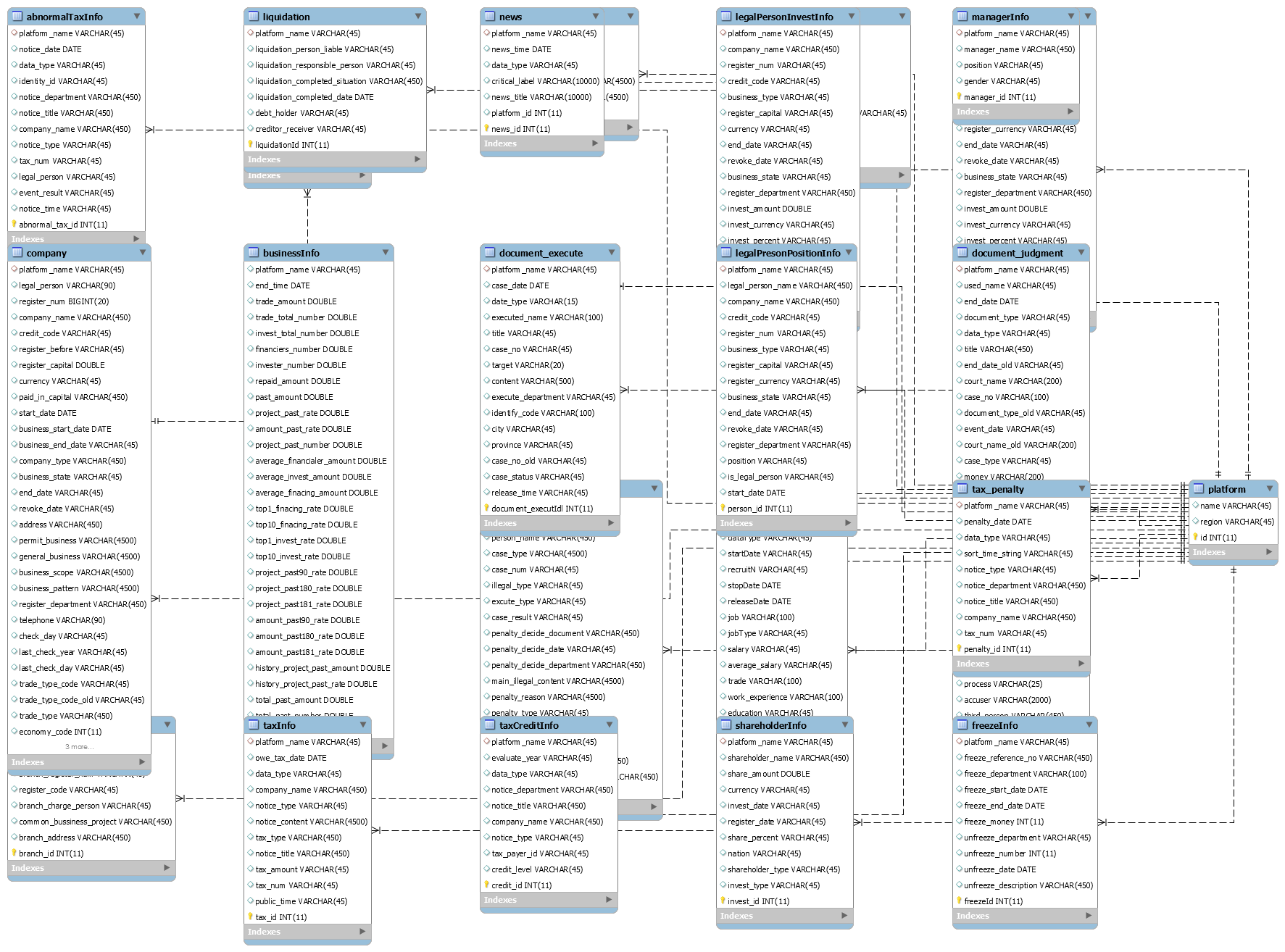
- platform表中存储了P2P网贷平台的基本名称和城市信息,该表中的平台名时其他所有表的关联外键。company表中存储了每个平台下的子公司具体的工商信息,其中包括公司名,注册资金,注册人,地址等公司的基本信息。
- 司法维度:通过documentJudgment表和documentExecute表分别存储了对应平台的司法信息中的裁判文书信息和执行公告信息。
- 工商信息维度:通过company表,freezeInfo表,liquidation表,administrationPenalty表,shareholderInfo表,managerInfo表,legalPersonInvestInfo表,legalPersonPositionInfo表,changeInfo表,businessInvestInfo表,branchInfo表和equityPledged表分别存储了对应平台的工商信息中的企业基本照面信息,股权冻结历史信息,清算信息,行政处罚历史信息,股东及出资人信息,主要管理人员信息,法人代表在其他企业任职信息,变更信息,企业对外投资,分支机构信息和股权出质历史信息。
- 税务信息维度:通过taxInfo表,taxPenalty表,abnormalTaxInfo表和taxCreditInfo表分别存储了对应平台的税务信息中的欠税信息,税务处罚信息,税务非正常用户信息和企业纳税信用信息。
- 舆情信息维度:通过news表存储了每个平台的新闻舆情信息,其中包含了新闻的类型,重要标签,新闻标题和舆情详细内容等信息。
- 招聘信息维度:通过employInfo表存储了每个平台的每个时期的招聘信息,其中包含了职位需求,薪水,福利,地址等基本招聘信息。
- 经营信息维度:通过表businessInfo和表wdzjInfo分别存储了对应平台的经营信息,其中包含了交易额,人均投资数量,投资总额等基本信息。
- 违规信息维度:通过ICP表和bankDepository表分别存储了对应平台企业的ICP违规信息和银行存管信息。
模型选择及建模
参考相关研究和历史文献,以往学者计算行业风险时采取的建模方法包括多变量因子分析法,熵权法,Logistic回归法,BP神经网络等等。通过分析P2P行业的特点,发现P2P企业大多存在数据形式多样、结构不一致和缺失值较多等特点,加上风险值作为一个主观估值,很难判断其估计是否准确,因此对数据分别进行了机器学习建模与人工建模,并将两者的结果进行比较,相互验证。
机器学习建模
数据来源与变量选取
数据选自800余家P2P平台自2015年1月1日至今的全部数据,对于平台的基本信息,根据数据可获得性共选取营业天数(截止日期-开始日期)、成交量、平均利率、投资人数、平均借款期限、借款人数、累计待还金额、借款标数共计8个指标,本次研究计算了上述各平台在数据期内每个指标的均值和变异系数(标准差/均值),共计16个变量,以表示该平台的交易特征。均值表示了每个指标的水平值,变异系数表示了波动性大小。
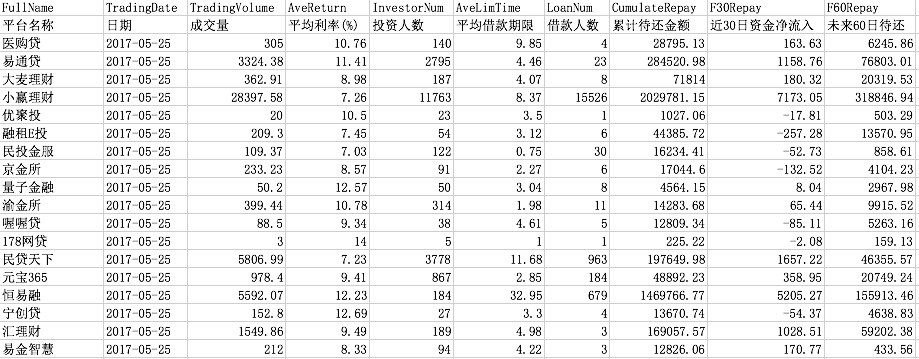
将网贷之家爬取到的问题平台(提现困难、跑路、停业)标记为1,正常平台标记为0,进行预测。

机器学习模型
将数据按照正常平台和问题平台二分类,从而奖惩问题转化为一个二分类问题。经过筛选,总共有352家企业数据符合要求,其中问题企业有58家。正常企业数据和问题企业数据个数存在严重的不匹配问题。针对这个问题,采用SMOTE方法,对少数类样本进行过采样,以使两类数据达到平衡。
本次研究选取三个统计模型(随机森林、决策树、SVM)来开展研究。通过比较不同模型的结果以判断风险识别与预测的稳定性与可靠性,并确定合适的预测模型; 综合考虑各个模型所提供的信息以分析P2P 平台的风险特征。对3个机器学习模型进行五折交叉验证。
结果分析
| 模型 | AUC |
|---|---|
| 随机森林 | 0.9333 |
| 决策树 | 0.8484 |
| SVM | 0.9393 |
SVM方法的测试集准确率最高,达到了94%的准确率。随机森林的准确率次之,也达到了93%的测试集准确率。相比随机森林和SVM两个模型,决策时的准确率不够理想,只有85%。
在后期进一步分析中,尝试在经营维度的基础上增加司法、税务、工商等维度信息,但是准确率不太高。分析有如下几点原因:
- 数据为文本型和离散性数据,数据分析难度大;
- 数据随时间分布不均;
- 各平台数据分布不均,尤其部分平台数据缺失情况严重。
虽然经营数据做预测准确率较高,但是由于经营数据大部分由网贷之家公布,非官方平台披露的数据,其数据公信力远不如司法、税务等平台披露的数据。因此为了解决这一问题,进行了人工模型的构建。
人工建模
层次分析法略。
2种建模方法比较
通过分析P2P行业的特点,发现P2P企业大多存在数据形式多样、结构不一致和缺失值较多等特点,加上风险值作为一个主观估值,很难判断其估计是否准确,因此需要采用人工建模法,即人工比较各指标对风险影响的大小,使用层次分析法确定各指标权重,生成企业风险值。同时,由于人工建模法的权重定义存在主观因素,机器学习建模可以解决这一问题,因此才采用两种方法建模,并对两种方法的优劣进行比较。
- 机器学习模型在处理0,1二分类问题效果较好,能够有效的判别企业是否有风险,但不能得到企业的具体风险值,也不能比较企业之间的相对风险。
- 人工模型能够确定各维度的重要性,识别具体风险带你,有效地对P2P企业进行更为详细的风险评估, 生成风险值。但由于人工建模的变量权重是人为比较权衡的,因此存在一定的主观因素,其准确性会下降。
可视化展示
网站架构
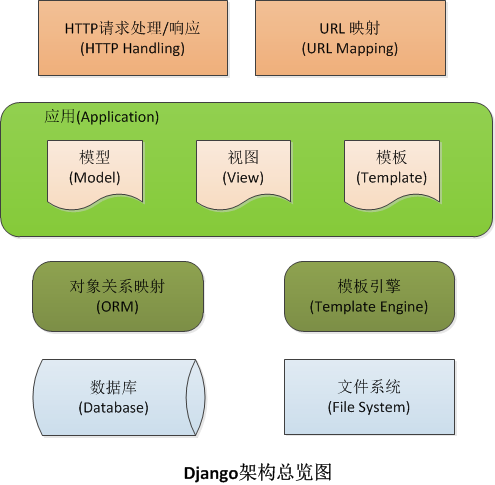
为了方便查询典型p2p平台风险状况,我们系统实现了一个可视化展示网站,通过D3可视化技术直观地展现出p2p企业存在的风险。
后台django服务器接受前端发来的post/ajax请求,解析该请求后,通过分发控制器将请求分配到对应的业务处理模块进行业务处理,model层通过Django向数据库发出数据请求,Django根据请求自动生成对应的sql语句,向对应的一个或多个数据DB申请对应所需处理的数据,最后将数据返回给model层进行处理;对应的model获取相应的数据后,讲述据带入对应的模型进行计算处理,得出用户想要的结果,将结果以json的形式返回给前端客户端,前端通过D3.js解析所得到json数据,将这些数据以可视化的形式展现出来。
网页展示
网站首页

默认显示风险值最高的前3个P2P企业,可以通过搜索找到目标企业。
P2P企业区域分布热点图
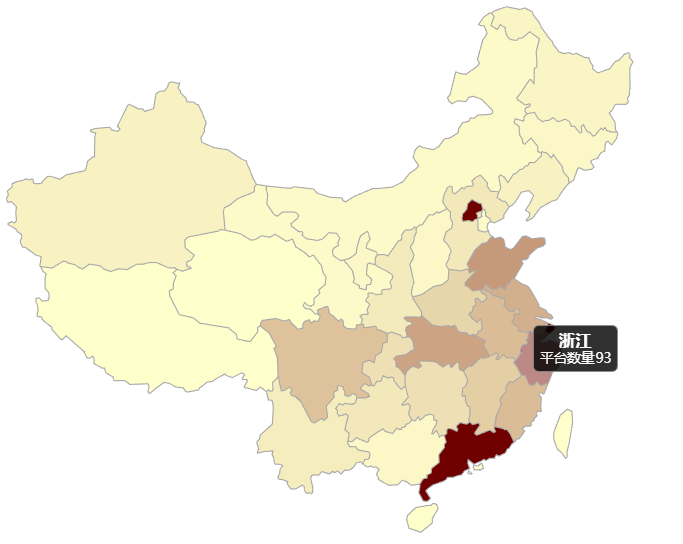
可以直观的发现P2P企业主要集中出现在北上广江浙一带。
某企业风险整体分析
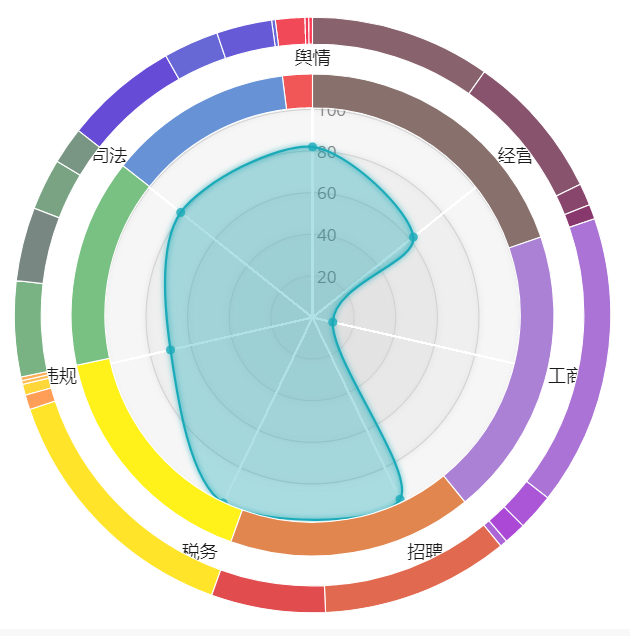
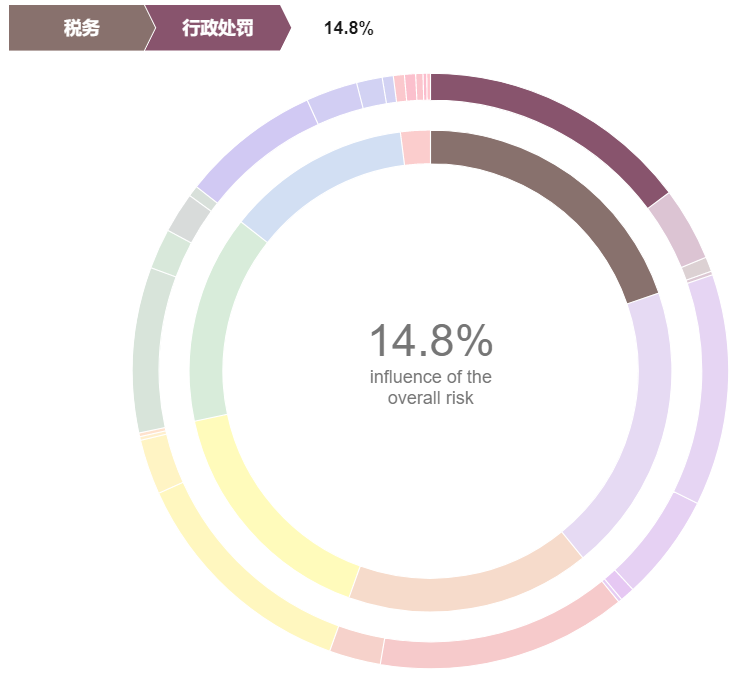
通过雷达图和扇形图的结合,直观的展现某一企业7个维度的风险值大小,以及不同维度对整体风险值的影响比例。
代码主要实现思路:通过div标签得到visibility 属性控制雷达图和比例值之间的显示切换。数据通过前端ajax请求,后台以json的形式返回。
某企业工商维度风险概览


7个不同的风险维度都会有一个自已的风险值,分别表示该领域的风险大小,通过前端的get请求从后端获取得到。风险值的圆圈通过D3的Path绘制出来,并通过transform的translate绘制动画效果。
某公司司法维度案件关系网络
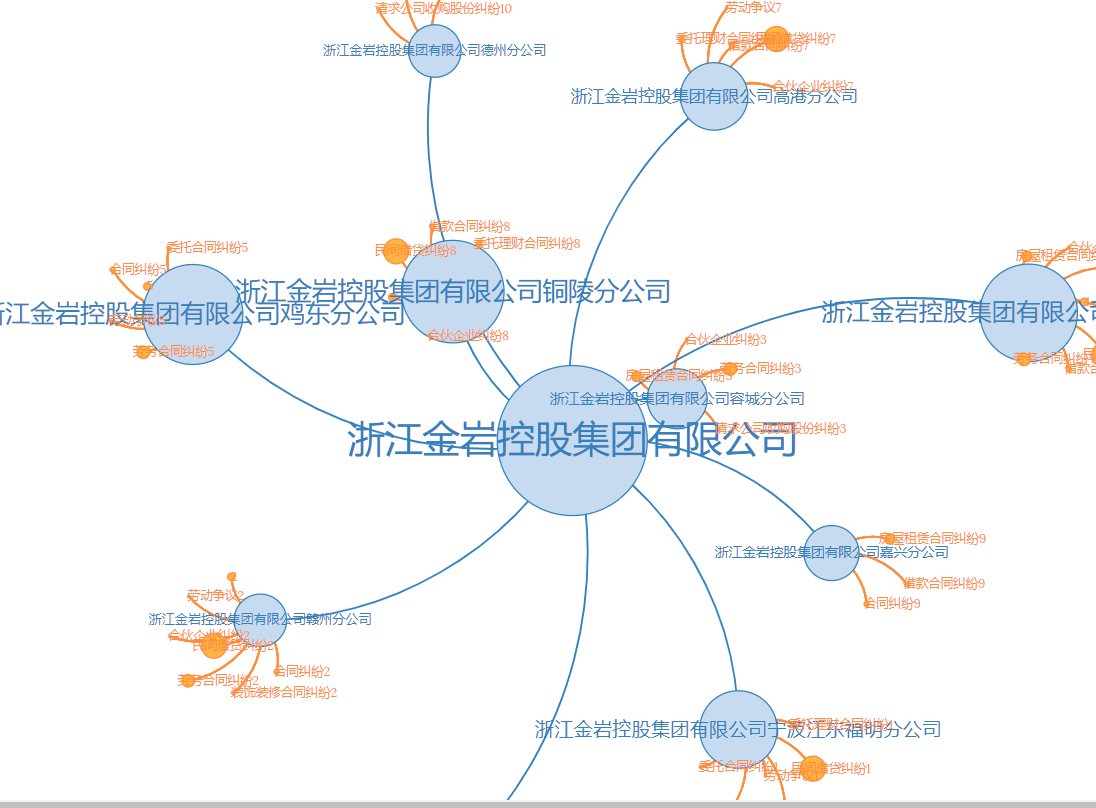
司法维度案件关系网络通过D3的force layout,表示该企业以及它的子公司在司法方面所有的官司数量与关联关系。数据通过前端ajax请求,后台以json的形式返回。
某公司成交量和利率变动图
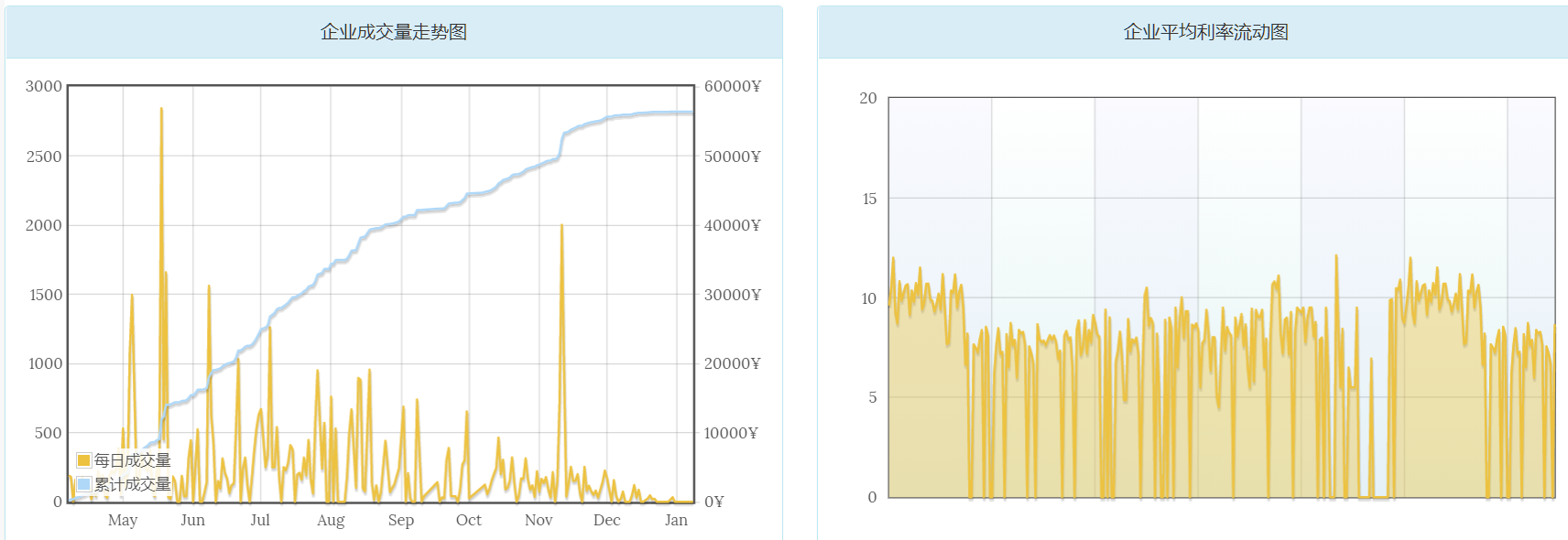
通过bootstrap的flot-chart绘制出该企业近期的成交量走势图和该企业的平均利率随时间的动态变化图。通过走势图我们能直观的发现,该企业在近期的成交量由明显的下降,甚至趋近于0说明该企业近期有一个很大的风险点。
通过这两张图可以比较直观的分析出该企业近期的一个经营情况。数据通过前端ajax请求,后台以json的形式返回。
某公司舆情维度中的词云展示

通过从网络中爬取有关该企业所有额舆情信息(数据来源于各大新闻媒体),对这些舆情信息做一个简单的分词处理,便可得到一个根据舆情的关键词词频绘制而出的词云。该词云的绘制借助了D3的某个开源项目——d3.layout.cloud.js,数据通过前端ajax请求,后台以json的形式返回。
某公司招聘维度下招聘人数比例图
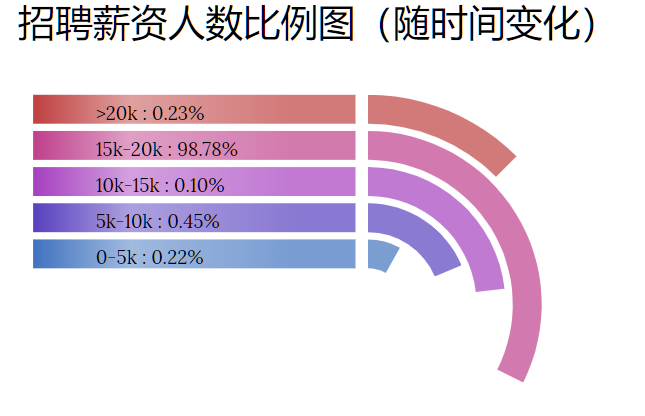
是一个扇形图的变形版本,能够比较直观的显示出某次招聘中每类招聘所占比例。该图的最大特点在于能够比较方面的展示每一次招聘中每个维度的分布情况。(这是一个动图: 设置时间间隔,每隔一段时间选取新的数据绘制该图)。数据通过前端ajax请求,后台以json的形式返回。
某公司招聘维度下招聘人数走势图和招聘学历分布图
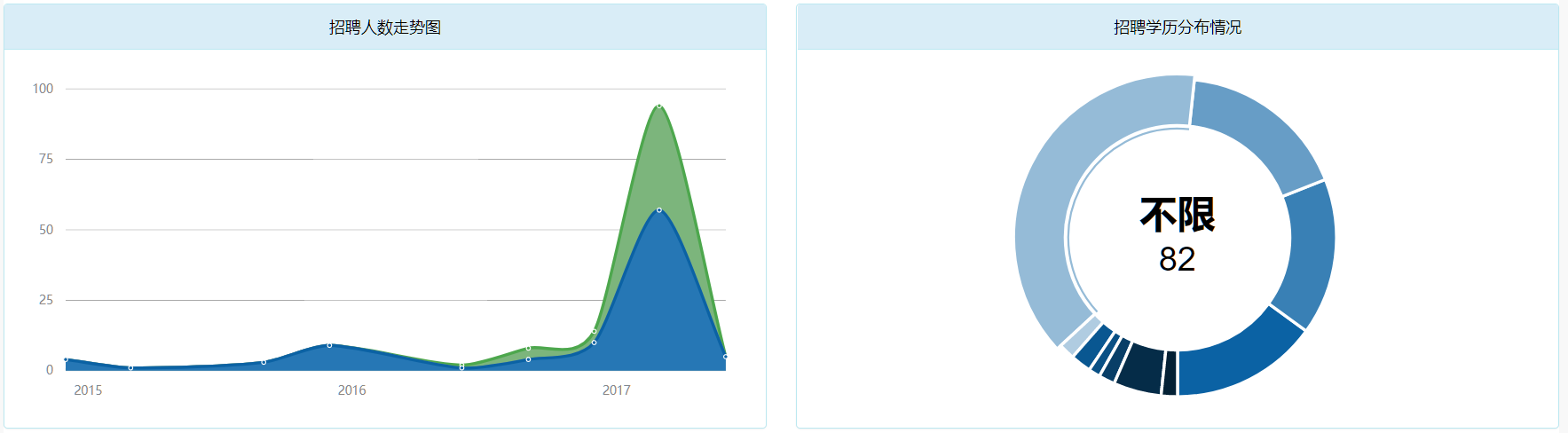
能展示出企业的一个招聘情况。通过上图我们可以分析出,在2017年年中,该企业突然进行了大规模的招聘活动,而且根据招聘学历分布图,该企业在这段时间内大量的招聘了没有学历的人,这是一个很强的风险点。
该图的绘制借助了bootstrap的morris-area-chart和morris-donut-chart。数据通过前端ajax请求,后台以json的形式返回。